
MySQL 환경에서 많은 데이터를 한 번에 삽입하는 경우가 발생했다. JPA 를 통해서 saveAll() 메서드를 사용하였고, 1개 혹은 정말 소수의 쿼리가 발생을 기대했다.
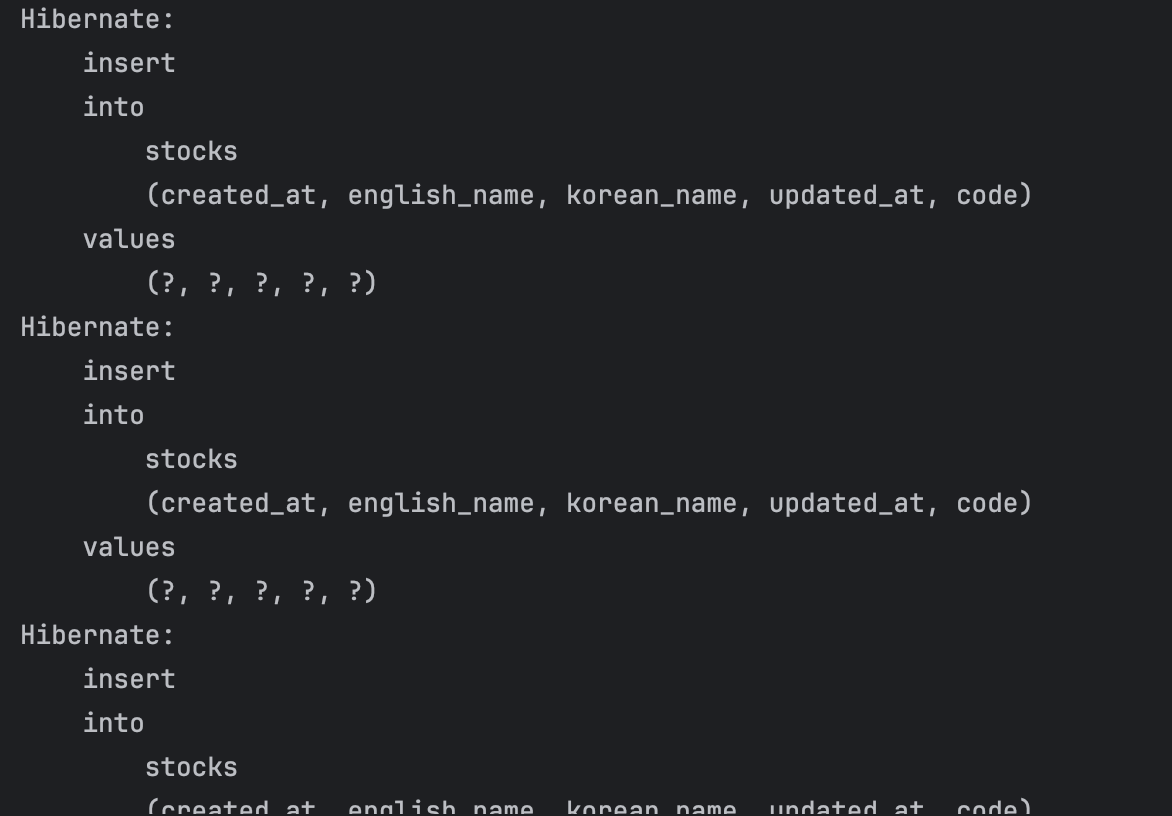
하지만 실제 쿼리는 아래와 같이 레코드 수 만큼 발생했다. 이러한 원인을 파악하고 원했던 대로 1건의 쿼리로 변경시켜보자.
1. save()
@Transactional
@Override
public <S extends T> S save(S entity) {
Assert.notNull(entity, "Entity must not be null.");
if (entityInformation.isNew(entity)) {
em.persist(entity);
return entity;
} else {
return em.merge(entity);
}
}
save 메서드는 INSERT 문 하나마다 @Transactional 어노테이션이 걸려있다. 따라서 N 번의 @Transactional이 그대로 발생한다.
@Transactional 은 AOP 로 동작하는데, 커밋 또는 롤백을 위해 추가적인 리소스를 사용하고 있다.
save() 를 통해 저장한 레코드는 총 385 건이며 2555 ms 지연 시간이 발생했다.
2024-11-05T22:22:25.640+09:00 INFO 14173 --- [mock-stock-server] [onPool-worker-1] c.m.i.s.d.s.application.StockService : save() insert took 2552 ms
처리 건수에 비해서 심각하게 많은 처리 시간처럼 보인다.
2. saveAll()
List 에 대해서 save 를 처리하면 IDE 에서도 saveAll() 메서드를 권한다.
@Transactional
@Override
public <S extends T> List<S> saveAll(Iterable<S> entities) {
Assert.notNull(entities, "Entities must not be null!");
List<S> result = new ArrayList<>();
for (S entity : entities) {
result.add(save(entity));
}
return result;
}
실제 코드를 보면 여러 건의 Insert 문을 하나의 @Transactional 로 묶고 있다. 하지만 결국 단 건들에 대해서 save 메서드가 실행된다.
하지만 save() 도 결국 트랜잭션 어노테이션을 가지고 있지 않은가??
이 부분은 트랜잭션 전파 속성 때문에 saveAll() 내부의 save() 메서드는 새로운 트랜잭션을 생성하지 않고 부모 트랜잭션을 재사용하기 때문이다. 그렇기에 트랜잭션은 1 번만으로 이루어졌다고 볼 수 있다.
2024-11-05T22:21:43.955+09:00 INFO 14113 --- [mock-stock-server] [onPool-worker-1] c.m.i.s.d.s.application.StockService : saveAll() insert took 971 ms
그 결과로 실제 동일한 쿼리가 발생하지만 971 ms 처리 시간이 발생했다.
3. Bulk Insert
실제로 원했던 건 N 개의 쿼리가 아닌 단 하나의 쿼리다. 하나의 쿼리로 모든 삽입을 진행하기 위해서는 아래와 같은 쿼리가 필요하다.
INSERT INTO stocks (code, korean_name, english_name) VALUES
(?, ?, ?),
(?, ?, ?),
(?, ?, ?),
...
(?, ?, ?);
이를 위해서는 JPA 를 사용하기에는 어렵고 QueryDsl 을 사용할 수 있다. 하지만 새로운 의존성을 추가하기에는 부담이 있으니 JdbcTemplate 으로 구현해보고자 한다.
@Repository
@RequiredArgsConstructor
public class StockBulkRepository {
private final JdbcTemplate jdbcTemplate;
@Transactional
public List<StockDto> saveAll(List<Stock> stockList) {
String sql = "INSERT INTO stocks (code, korean_name, english_name) VALUES (?, ?, ?)";
jdbcTemplate.batchUpdate(sql, stockList, stockList.size(), (ps, stock) -> {
ps.setString(1, stock.getCode());
ps.setString(2, stock.getKoreanName());
ps.setString(3, stock.getEnglishName());
});
return StockDto.fromEntities(stockList);
}
}
새로운 레포지터리를 직접 선언했다. JdbcTemplate 의 batchUpdate() 메서드를 사용하였고 아래 처럼 실제 1 개의 쿼리 문만 보내는 것을 확인할 수 있었다.
2024-11-05T22:20:45.368+09:00 INFO 14026 --- [mock-stock-server] [onPool-worker-1] c.m.i.s.d.s.application.StockService : Bulk insert took 292 ms
실행시간도 292 ms 로 확연히 줄어든 것을 확인할 수 있다. 400건도 안되는 레코드에서도 성능 차이가 극심하니 다수의 레코드 삽입 처리는 Bulk Insert 를 사용하도록 하자.
추가로 InnoDB 에서는 하나의 쿼리로 여러 레코드를 삽입할 때 3 건 중 1 건의 중복이 발생한다면 나머지 2 건을 정상적으로 삽입하기에 사용하기에 더 편리하다. 이전에는 중복된 레코드를 찾아 제거하고 새로운 레코드만 삽입했지만 위 처럼 작성하면 신경쓰지 않아도 된다는 뜻이다. 당연히 검증이 불필요하다는 말은 아니다.