
9장 옵티마이저와 힌트
9.3 고급 최적화
서버의 옵티마이저는 실행 계획을 수립할 때 통계 정보와 옵티마이저 옵션을 결합해 최적의 실행 계획을 수립한다. 옵션은 크게 조인 관련 옵션과 스위치로 구분할 수 있다.
옵티마이저 스위치 옵션
스위치 옵션은 optimizer_switch 시스템 변수를 통해 제어한다.글로벌과 세션별 모두 설정할 수 있는 변수이므로 서버 전체 및 커넥션에 대해 설정할 수 있다.
MRR과 배치 키 액세스
Multi-Range Read 이다. 조인은 드라이빙 테이블에서 하나의 레코드를 읽어 드리븐 테이블의 일치하는 레코드를 찾는 방식이다. 이를 네스티드 루프 조인이라 한다. 내부적으로는 MySQL 엔진이 조인을 처리하지만, 레코드를 검색하고 읽는 것은 스토리지 엔진이 담당한다. 따라서 레코드를 찾고 읽는 스토리지 엔진에서는 아무런 최적화를 수행할 수 없다.
이를 위해 MySQL 서버는 조인 대상 테이블 중 하나로부터 레코드를 읽어 조인 버퍼에 버퍼링한다. 즉, 드라이빙 테이블의 레코드를 읽어 조인을 즉시 실행하지 않고 대상을 버퍼링한다. 이렇게 함으로써 스토리지 엔진은 읽는 레코드들을 데이터 페이지에 정렬된 순서로 접근해 디스크의 데이터 페이지 읽기를 최소화할 수 있다.
이러한 방식을 MRR 이라 하며, 실행 중인 조인 방식을 BKA (Batched Key Access) 조인이라 한다.
블록 네스티드 루프 조인
서버의 대부분 조인은 네스티드 루프 조인인데, 연결 조건이 되는 칼럼에 모두 인덱스가 있는 경우 사용되는 조인 방식이다.
네스티드 루프 조인과의 차이점은 조인 버퍼가 사용되는지 여부와 조인에서 드라이빙 테이블과 드리븐 테이블의 조인 순서이다.
조인은 드라이빙 테이블에서 일치하는 레코드 건수만큼 드리븐 테이블을 검색한다. 즉, 드리븐 테이블은 여러 번 읽는 다는 것이다. 그래서 드리븐 테이블 검색 시 인덱스를 사용할 수 없는 쿼리는 상당히 느려지며 옵티마이저는 최대한 인덱스를 사용할 수 있게 실행 계획을 수립한다.

- `dept_emp` 테이블의 `ix_fromdate` 인덱스를 이용해 레코드를 검색한다.
- 조인에 필요한 나머지 칼럼을 모두 `dept_emp` 테이블로부터 읽어서 조인 버퍼에 저장한다.
- `employees` 테이블의 프라이머리 키를 이용해 조건에 만족하는 레코드를 검색한다.
- 3번에서 검색된 결과에 2번의 캐시된 조인 버퍼의 레코드를 결합해 반환한다.
위에서 중요한 점은 조인 버퍼가 사용되는 쿼리에서는 조인 순서가 거꾸로인 것처럼 실행되는 것이다. `employee` 테이블을 기준으로 병합했다는 뜻이다. 이대문에 결과의 정렬 순서가 흐트러질 수 있다.
인덱스 컨디션 푸시다운


위 그림은 `last_name='Action'` 조건으로 인덱스 레인지 스캔 후 레코드를 찾고, `first_name LIKE '%sal'` 조건을 파악하는 과정이다. 위 그림에서는 첫 번째 조건을 부합하는 레코드가 3건이지만 만약 10만건 중 1 건만 사용한다면 불필요한 작업이 너무 많아진다.
단순히 생각해보면 인덱스를 처리할 때 두 번째 조건도 한 번에 처리하면 될 것 같다. 사실 두 번째 조건을 누가 처리하느냐에 따라 인덱스에 포함된 칼럼을 사용할 지, 테이블에 존재하는 칼럼을 사용할 지 결정된다. 인덱스 비교 작업은 실제 InnoDB 스토리지 엔진이 수행하지만, 테이블에서 비교 작업은 MySQL 엔진이 수행하는 작업이다.
MySQL 5.6 버전부터는 이렇게 인덱스를 범위 제한 조건으로 사용하지 못한다고 하더라도 인덱스에 포함된 칼럼의 조건이 있다면 모두 모아 스토리지 엔진으로 전달할 수 있게 핸들러 API 가 개선되었다. 즉, 인덱스를 이용해 최대한 필터링까지 완료해 1건의 레코드만 테이블 읽기를 수행한다는 뜻이다.
고도의 기술력을 요하는 기능은 아니지만 쿼리의 성능이 수십 배로 향상될 수 있는 중요한 기능이다.
인덱스 확장
`use_index_extensions` 옵션은 InnoDB 스토리지 엔진을 사용하는 테이블에서 세컨더리 인덱스에 자동으로 추가된 프라이머리 키를 활용할 수 있게 할지를 결정하는 옵션이다.
인덱스 머지
대부분 옵티마이저는 테이블별로 하나의 인덱스만 사용하도록 실행 계획을 수립한다. 해당 옵션은 하나의 테이블에 대해 2개 이상의 인덱스를 이용해 쿼리를 처리한다. 쿼리에서 한 테이블에 대한 WHERE 조건이 여러 개 있더라도 하나의 인덱스에 포함된 칼럼에 대한 조건만으로 인덱스를 검색하고, 나머지는 읽어온 레코드에서 체크하는 형태로만 사용하는 것이 일반적이다.
하지만 쿼리에 사용된 각 조건이 서로 다른 인덱스를 활용할 수 있고 그 조건을 만족하는 레코드가 많을 것으로 예상되면 인덱스 머지 실행 계획을 선택한다.
인덱스 머지 - 교집합
두 개의 칼럼이 존재하고 각각의 인덱스가 존재한다면 인덱스 머지 최적화 기법을 사용할 수 있다. 첫 번째, 두 번째 칼럼을 A, B 라 하자.
A 를 만족하는 게 253 건, B 를 만족하는게 10,000 건이며, A,B 를 모두 만족하는게 14 건이라 하자. 어떤 조건을 먼저 사용하더라도 버리는 레코드가 많기에 비효율적이 매우 큰 상황이다. 이때 옵티마이저는 각 인덱스를 검색해, 두 결과의 교집합만을 찾아 반환할 수 있다.
인덱스 머지 - 합집합
인덱스 머지의 2 개 이상의 조건이 각 인덱스를 사용하되 OR 연산자로 연결된 경우에 사용하는 최적화이다.
인덱스 머지 - 정렬 후 합집합
Union 알고리즘은 두 결과 집합의 중복을 제거하기 위해 정렬된 결과를 필요할 때이다.
세미 조인
다른 테이블과 실제 조인을 수행하지는 않고 단지 다른 테이블에서 조건에 일치하는 레코드가 있는 지 없는 지만 체크하는 형태의 쿼리다.
테이블 풀-아웃
세미 조인의 서브쿼리에 사용된 테이블을 아우터 쿼리로 끄집어낸 후에 쿼리를 조인 쿼리로 재작성하는 형태의 최적화이다. 이는 서브쿼리 최적화가 도입되기 전부터 수동으로 쿼리를 튜닝하던 대표적인 방법이다.
퍼스트 매치
First Match 최적화 전략은 IN 형태의 세미 조인을 EXISTS 형태로 튜닝하는 것과 비슷한 방법으로 실행된다.

루스 스캔
GROUP BY 최적화 방법에서의 루스 인덱스 스캔과 비슷한 읽기 방식이다. 루스 인덱스 스캔을 통해 유니크한 `dept_no` 만 읽어 부서 테이블을 조회한다면 효과적으로 실행할 수 있다.

구체화
세미 조인에 사용된 서브쿼리를 통째로 구체화해서 쿼리를 최적화한다는 의미다. 여기서 구체화는 내부 임시 테이블을 생성한다는 것이다.
중복 제거
세미 조인 서브쿼리를 일반적인 INNER JOIN 쿼리로 바꿔 실행하고 마지막에 중복된 레코드를 제거하는 방법이다.

컨디션 팬아웃
조인을 실행할 때 테이블의 순서는 쿼리의 성능에 매우 큰 영향을 미친다. 그래서 옵티마이저는 여러 테이블이 조인되는 경우 가능한 일치하는 레코드 건수가 적은 순서대로 조인을 실행한다.
파생 테이블 머지
서버 내부적으로 임시 테이블이 만들어지는 경우 레코드 건수가 많아지면 디스크에 저장된다. 따라서 이러한 파생 테이블로 만들어지는 서브쿼리를 외부 쿼리와 병합해서 서브 쿼리 부분을 제거하는 최적화가 도입되었다.
인비저블 인덱스
인덱스의 가용 상태를 제어할 수 있는 기능이다.
스킵 스캔
인덱스의 핵심은 정렬이다. 이로 인해 인덱스 구성 칼럼의 순서가 매우 중요하다. (A, B, C) 칼럼으로 구성된 인덱스는 B, C 로 구성된 조건에 활용되기 어렵다. 인덱스 스킵 스캔은 제한적이지만 이러한 제약 사항을 뛰어넘을 수 있는 최적화 기법이다.
인덱스의 선행 칼럼이 조건절에 사용되지 않더라도 후행 칼럼만으로도 인덱스를 이용한 쿼리 성능 개선이 가능하다. 옵티마이저는 테이블에 존재하는 모든 선행 칼럼 값을 가져와 조건이 있는 것 처럼 최적화한다. 만약 선행 칼럼이 매우 다양한 값을 가지면 비효율적일 수 있지만 소수의 유니크한 값이라면 충분히 사용할 수 있다.
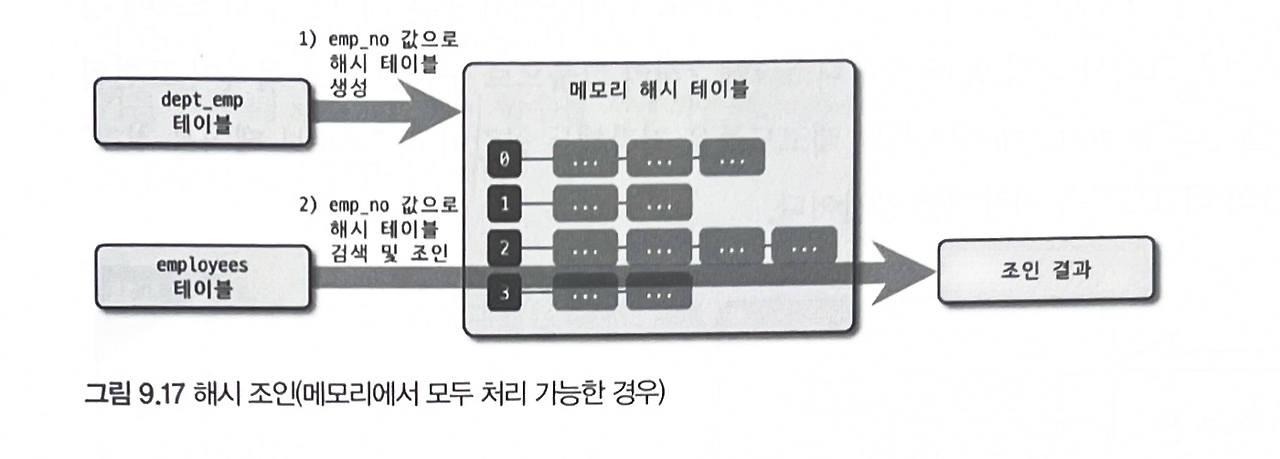
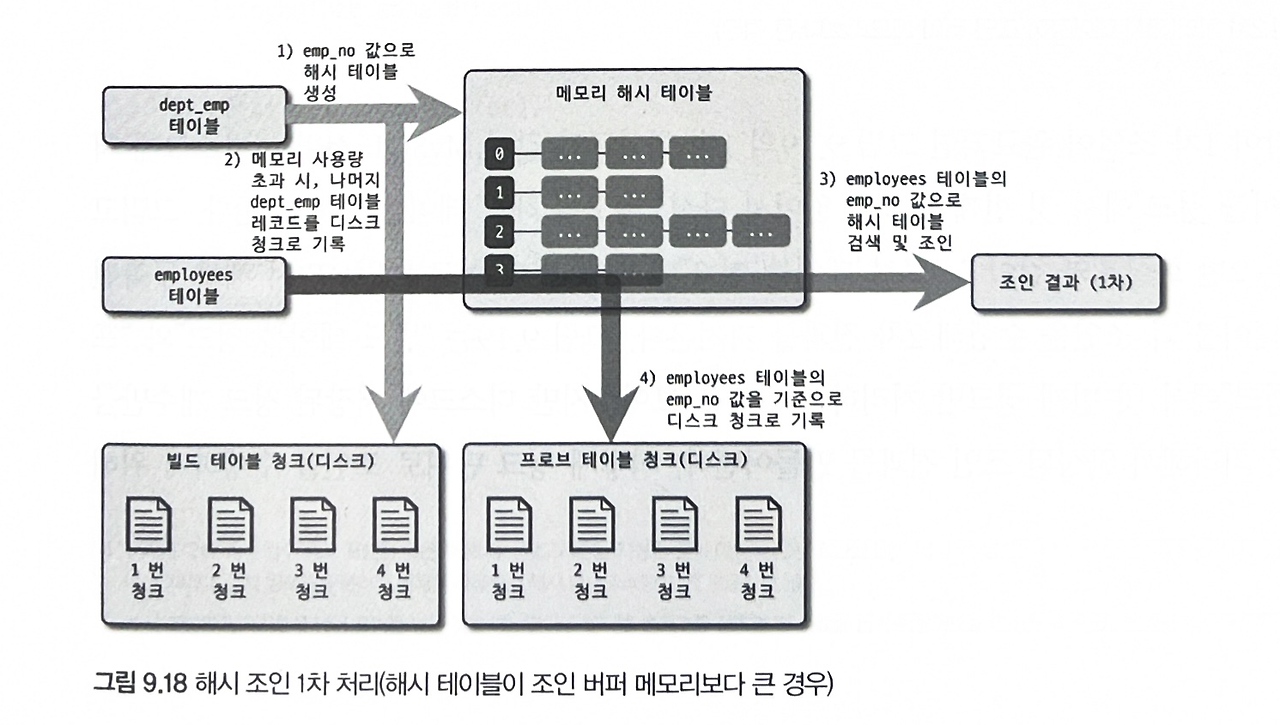
해시 조인

A 지점은 쿼리가 실행되어 첫 레코드를 찾은 시점이고, B 지점은 쿼리 종료 지점이다.
물론 해시 조인이 성능이 빠르지만 첫 번째 레코드를 찾는데에는 긴 시간이 걸린다. 즉, 해시 조인 쿼리는 최고 스루풋 전략에 적합하며, 네스티드 루프 조인은 최고 응답 속도 전략에 적합하다.
일반적으로 해시 조인은 빌드 단계와 프로브 단계로 나뉘어 처리된다. 빌드 단계는 조인 대상 테이블 중 레코드 건수가 적어 해시 테이블로 만들기 용이한 테이블을 골라 메모리에 해시 테이블을 생성하는 작업이다. 이때 사용되는 원본 테이블을 빌드 테이블이라 한다. 그리고 프로브 단계에서는 나머지 테이블의 레코드를 읽어 해시 테이블의 일치 레코드를 찾는 과정을 의미한다.
인덱스 정렬 선호
옵티마이저는 ORDER BY 혹은 GROUP BY 를 인덱스를 사용해 처리 가능한 경우 쿼리 실행 계획에서 인덱스의 가중치를 높이 설정해 실행된다. 두 개의 인덱스 중 가끔 잘못된 실행 계획으로 비효율적인 인덱스가 선택될 수 있다.
이전에는 이런 경우를 방지해 특정 인덱스를 사용하지 못하도록 힌트를 사용하거나 했다. 하지만 이후 인덱스에서 ORDER BY 를 위한 인덱스에 너무 많은 가중치를 부여하지 않도록하는 옵션이 추가되었다.
조인 최적화 알고리즘
MySQL 에는 조인 쿼리의 실행 계획 최적화를 위한 2가지 알고리즘이 있다. 아직도 테이블의 개수가 많아지면 최적화 실행 계획을 찾기 어려워지고, 계획 수립에만 몇 분이 걸릴 수도 있다.
Exhaustive 검색 알고리즘

FROM 절에 명시된 모든 테이블 조합에 대해 실행 계획의 비용을 계산해 최적의 조합 1개를 찾는 방법이다. 테이블이 20개라면 가능한 조인 조합은 20! 이다.
Greedy 검색 알고리즘

4개의 테이블이 처리될 경우 최적의 조인 순서를 검색하는 방법을 그림으로 보여준다.
말 그대로 그때그때 최적의 조인 순서를 하나씩 찾아가는 방법이다.
9.4 쿼리 힌트
개발자가 직접 MySQL 에 부족한 실행 계획을 수립할 수 있다.
인덱스 힌트
옵티마이저 힌트들은 모두 MySQL 서버를 제외한 다른 RDBMS에서는 주석으로 해석하기 때문에 ANSI-SQL 표준을 준수한다고는 볼 수 있다. 그래서 가능하다면 인덱스 힌트보다는 옵티마이저 힌트를 사용할 것을 추천한다. 또한 인덱스 힌트는 SELECT 명령과 UPDATE 명령에서만 사용할 수 있다.
STRAIGHT_JOIN
테이블 조인 시 순서를 고정하는 역할을 한다.
USE INDEX / FORCE INDEX / IGNORE INDEX
인덱스 힌트는 사용하려는 인덱스를 가지는 테이블 뒤에 힌트를 명시한다. 대체로 옵티마이저는 인덱스 선택은 무난하지만 3~4 개 이상의 컬럼을 포함하는 비슷한 인덱스가 여럿 있다면 가끔 실수를 한다.
이를 해결하기 위해 특정 테이블의 인덱스를 사용하도록 권장하거나 강제 혹은 사용하지 못하게 권장한다.
SQL_CALC_FOUND_FOWS
LIMIT 을 사용하는 경우 해당 수 만큼 레코드를 찾으면 즉시 검색을 멈춘다. 하지만 해당 힌트가 있으면 끝까지 검색을 수행한다. 이를통해 LIMIT 을 제외한 조건에 만족하는 레코드가 전체 몇 건인 지 알아낼 수 있다.
옵티마이저 힌트
옵티마이저 힌트는 영향 범위에 따라 다음 4개 그룹으로 나뉜다.
- 인덱스 : 특정 인덱스의 이름을 사용할 수 있는 옵티마이저 힌트
- 테이블 : 특정 테이블의 이름을 사용할 수 있는 옵티마이저 힌트
- 쿼리 블록 : 특정 쿼리 블록에 사용할 수 있는 옵티마이저 힌트로서 특정 쿼리 블록의 이름을 명시하는 것이 아니라 힌트가 명시된 쿼리 블록에 대해서만 영향을 미치는 옵티마이저 힌트
- 글로벌(쿼리 전체) : 전체 쿼리에 대해서 영향을 미치는 힌트
이 구분으로 인해 힌트의 사용 위치가 달라지는 것은 아니다. 그리고 힌트에 인덱스 이름이 명시 될 수 있는 경우를 인덱스 수준의 힌트로 구분하고 테이블 이름까지만 명시될 수 있는 경우를 테이블 수준의 힌트로 구분한다. 또한 특정 힌트는 테이블과 인덱스의 이름을 모두 명시할 수도 있지만 인덱스의 이름을 명시하지 않고 테이블 이름만 명시할 수도 있는데 이런 경우는 인덱스 테이블 수준의 힌트가 된다.
'etc > Book' 카테고리의 다른 글
| [객체지향의 사실과 오해] 1장 협력하는 객체들의 공동체, 2장 이상한 나라의 객체 (1일차) (9) | 2024.11.04 |
|---|---|
| [Real MySQL 8.0] 10장 실행 계획 (9일차) (1) | 2024.11.02 |
| [Real MySQL 8.0] 9장 옵티마이저와 힌트 (1) (7일차) (0) | 2024.10.31 |
| [Real MySQL 8.0] 8장 인덱스 (2) (6일차) (1) | 2024.10.30 |
| [Real MySQL 8.0] 7장 데이터 암호화, 8장 인덱스 (1) (5일차) (1) | 2024.10.30 |